
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 액티비티 다이어그램
- sample
- class diagram
- 판다스
- 데이터
- Tutorial
- 코딩
- 만들기
- 데이터 관리
- Python
- example
- Enterprise Architect
- UML
- Turorial
- data
- 예제
- Activity Diagram
- 컴포넌트 다이어그램
- 엔터프라이즈 아키텍처
- Component Dagram
- 튜토리얼
- 클래스 다이어그램
- 파이썬
- 이론
- 데이터 처리
- 기초
- pandas
- 사용법
- 소프트웨어공학
- EA
- Today
- Total
목록예제 (11)
SW개발 지식 쌓기
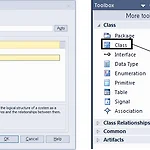 [ Enterprise Architect ] 클래스 다이어그램(Class Diagram) (Tutorial)
[ Enterprise Architect ] 클래스 다이어그램(Class Diagram) (Tutorial)
■ Class Diagram l Enterprise Architect 12.1 version - 클래스 다이어그램 생성 및 그리기 UML Structural -> Class 선택 드래그 앤 드롭을 통해서 사용하고자 하는 요소 선텍 수정이 필요한 경우 생성된 요소를 더블 클릭 한다. - 클래스 다이어그램 함수, 변수 넣기 클래스 다이어그램에 함수와 변수를 넣는 방법은 세 가지 방법이 있다. [1] Diagram element 좌 클릭 -> 돋보기 선택 [2] 파랑색(Attribute) 또는 빨강색(Operation) 선택 [3] Diagram elment 우 클릭 -> Features & Properties -> Attributes... 또는 Operations... 선택 * Diagram element ..
 [ Enterprise Architect ] 화면 구성, 프로젝트 구성 (Tutorial)
[ Enterprise Architect ] 화면 구성, 프로젝트 구성 (Tutorial)
■ Enterprise Architect 화면 구성 l Enterprise Architect 12.1 version [1] Project Browser : EA Project List [2] Tool Box : UML 다이어그램을 그리기 위한 도구 모음 [3] UML Draw : UML 다이어그램을 작성하기 위한 부분 [4] Properties : UML 다이어그램의 정보 표시 [5] Menu Bar : EA 메뉴들 모음 ■ 프로젝트(Project) 구성 l Enterprise Architect 12.1 version - 프로젝트 구조
 판다스(Pandas) 튜토리얼(tutorial) - 시계열(Time Series) 데이터 (Data)
판다스(Pandas) 튜토리얼(tutorial) - 시계열(Time Series) 데이터 (Data)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 시계열 Pandas는 주기 변환 중에 리샘플링 동작을 수행하기 위한 간단하고 효율적인 기능을 가진다. 시계열 데이터 생성 및 시계열 인덱스 변환 [108] 2012년 1월 1일 부터 100일을 초 주기로 생성 * 생성시 파라미터로 입력되는 freq는 다음과 같다. Alias Description B business day frequency (주말이 아닌 평일) C custom business day frequency D calendar day frequency (일) W weekly frequency (주-일요일) M month end frequency (각 달의 마지막 날) BM business month end f..
 판다스(Pandas) 튜토리얼(tutorial) - 변형(Reshaping),스택(stack),피봇테이블(pivot_table)
판다스(Pandas) 튜토리얼(tutorial) - 변형(Reshaping),스택(stack),피봇테이블(pivot_table)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 변형 Stack DataFrame의 열에 있는 단계를 stack() 메소드를 통해 압축하기 [95] 내장 함수인 zip 메소드를 통해서 리스트 자료형 생성 * zip 메소드는 반경가능한 자료형 여러개를 입력으로 받는 메소드이다. 예제는 다음과 같다. * list(zip([1, 2, 3], [4, 5, 6])) * [(1, 4), (2, 5), (3, 6)] * list(zip([1, 2, 3], [4, 5, 6], [7, 8, 9])) * [(1, 4, 7), (2, 5, 8), (3, 6, 9)] * list(zip("abc", "def")) * [('a', 'd'), ('b', 'e'), ('c', 'f')] [9..
 판다스(Pandas) 튜토리얼(tutorial) - 그룹핑(Grouping)
판다스(Pandas) 튜토리얼(tutorial) - 그룹핑(Grouping)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 그룹화 그룹화는 다음 단계 중 하나 이상을 포함하는 단계를 말한다. 몇 가지 기준에 따라 그룹으로 데이터 분할 독립적으로 각 그룹에 기능 적용 결과를 데이터 구조로 결합 그룹화한 결과에 sum() 함수를 적용한 DataFrame 출력 [91] 'A','B','C','D' 컬럼을 가지고 각각의 컬럼 값을 가지는 Dataframe 생성 [92] DataFrame 출력 [93] 'A' 컬럼을 기준으로 그룹화하고 각 값을 합산한 값을 출력 * 'A' 컬럼의 문자인 'bar'와 'foo'로 그룹화 된것을 볼 수 있고, 정수값을 가진 'C','D' 컬럼만 sum() 함수 값을 반환한다. * 문자열 값을 가진 'B' 컬럼은 자동으..
 판다스(Pandas) 튜토리얼(Tutorial) - Merge(병합), join(중복), append(추가)
판다스(Pandas) 튜토리얼(Tutorial) - Merge(병합), join(중복), append(추가)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. Merge (병합) Concat Pandas는 Series, DataFrame 및 Panel 객체를 join / Merge 유형의 작업에서, 인덱스 및 관계 대수 기능에 대한 다양한 유형의 논리로 쉽게 합칠 수 있는 다양한 기능을 제공한다. Pandas 객체 합치기 [73] 10행 4열의 DataFrame에 랜덤한 값을 넣는다. [74] 생성된 DataFrame 출력 [75] DataFrame을 행을 기준으로 1-3행까지 4-7행까지 8-10행까지 나누어 pieces 리스트에 저장한다. * 리스트의 시작은 0부터 시작 * pieces[0]을 출력하면 df[:3]의 결과가 출력된다. * pieces[1]을 출력하면 df..
 판다스(Pandas) 튜토리얼(Tutorial) - 판다스 메소드(Pandas Method)
판다스(Pandas) 튜토리얼(Tutorial) - 판다스 메소드(Pandas Method)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 튜토리얼을 진행하기 위해서는 아래의 과정을 수행해야한다. 메소드 통계 일반적으로 메소드는 누락 된 데이터 (NaN)을 제외한다. 평균 값 출력 통계 - 열 기준 [61] Pandas의 내장 메소드인 mean()을 사용하여서 각 열의 평균 값을 출력한다. * 'F' 라벨의 경우 NaN 값이 포함되어 있지만 NaN 값을 제외하고 평균값이 계산된 것을 알 수 있다. 평균 값 출력 통계 - 행 기준 [62] df.mean(1)을 사용하면 각 행 기준의 평균 값을 출력한다. * '2013-01-01' 인덱스의 경우 NaN 값이 포함되어 있지만 NaN 값을 제외하고 평균값이 계산된 것을 알 수 있다. NaN 값이 있는 Serie..
 판다스(Pandas) 튜토리얼(Tutorial) - 누락 데이터(Nan data)
판다스(Pandas) 튜토리얼(Tutorial) - 누락 데이터(Nan data)
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 튜토리얼을 진행하기 위해서는 아래의 과정을 수행해야한다. 누락 데이터 처리 Pandas는 기본적으로 numpy.nan 값을 사용하여 누락된 데이터를 나타낸다. 기본적으로 nan 값은 계산에 포함되지 않는다. 색인 변경 / 추가 / 삭제 [55] df.reindex 메소드를 통해서 숫자로 구성된 인덱스 값을 날짜 값으로 변경하고, 기존 컬럼에 'E' 컬럼을 추가하여 df1 생성 [56] df1의 2013-01-01, 2013-01-02의 'E' 컬럼의 값을 1로 변경, 'E' 컬럼의 나머지 부분은 값이 없으므로 NaN 값 [57] df1 출력 NaN 데이터 값 삭제 [58] df1에 NaN 값을 가지고 있는 경우 해당 ..
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 튜토리얼을 진행하기 위해서는 아래의 과정을 수행해야한다. 데이터 선택 단일 열 선택 단일 열을 선택하는 방법은 다음과 같다. [23] df[ ] 대괄호 안에 컬럼 값을 입력하여서 단일 열을 선택할 수 있다. 특정 영역을 선택하는 경우 [ ]을 사용하여 선택한다. [24] df[시작지점:종료지점] 을 통해 데이터 프레임의 특정 영역을 선택할 수 있다. (입력 값을 index로 한 경우) [24] df[시작지점:종료지점] 을 통해 데이터 프레임의 특정 영역을 선택할 수 있다. (입력 값을 date로 한 경우) 라벨을 통한 선택 라벨을 사용하여 해당하는 행을 선택한다. [26] 이전 [5]에서 만든 dates 리스트에서 첫..
패키지 import 튜토리얼을 진행하기 위해서는 아래의 패키지를 import 해야한다. 튜토리얼을 진행하기 위해서는 아래의 과정을 수행해야한다. 데이터 보기 데이터 프레임의 상단과 하단 행을 보는 방법은 다음과 같다. [13] df.head 메소드를 통해 데이터 프레임이 최상단부터 출력되고 입력 값이 없는 경우 디폴트 값인 5개가 출력된다. 숫자 값을 입력하게 되면, 입력한 값 만큼 최상단부터 출력된다. [14] df.tail 메소드를 통해 데이터 프레임이 최하단부터 출력되고 입력 값이 없는 경우 디폴트 값인 5개가 출력된다. 숫자 값을 입력하게 되면, 입력한 값 만큼 최하단부터 출력된다. 인덱스와 컬럼을 보는 방법을 다음과 같다. [15] df.index 메소드를 통해 df에 존제하는 index 값을 ..